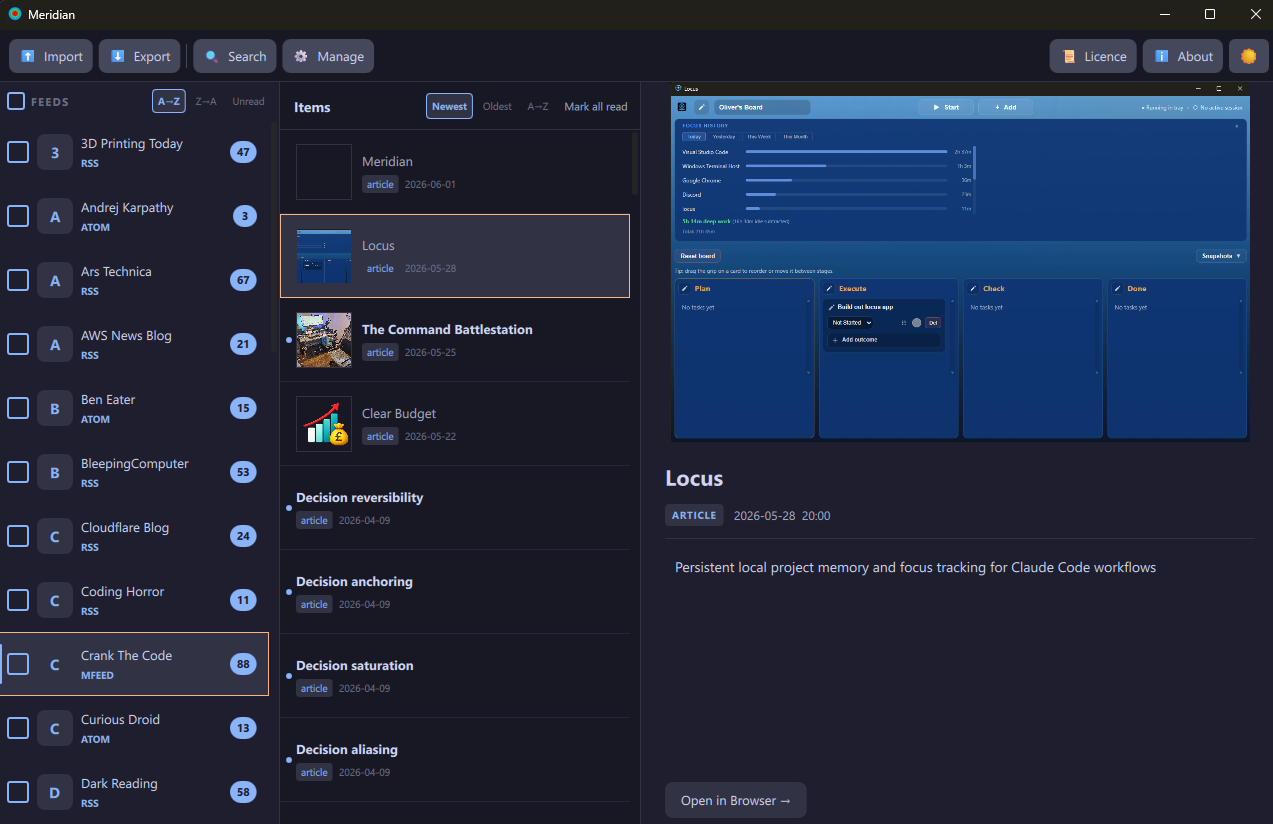
Meridian is a desktop feed reader built around an open publication protocol called MMSP.
Most feed readers answer a simple question:
What has been published?
Meridian was built to answer a broader one:
How should publication work in a world where content is no longer just articles?
Not only blogs. Not only RSS. Not only Atom.
Articles. Videos. Images. Machine-generated content.
Problem → System → Outcome
Problem. Modern publishing spans articles, podcasts, video, software releases and machine-generated content across disconnected platforms; RSS and Atom only partially cover it and most readers optimise for engagement rather than calm consumption.
System. A local-first desktop reader plus an open protocol, MMSP, that defines a machine-readable publication and discovery contract; Meridian is its reference implementation, unifying RSS, Atom and MMSP through one model with disciplined polling and full keyboard control.
Outcome. A consistent, calm, format-agnostic subscription experience and a working reference client that gives the protocol the authority a spec needs.
Why this exists
RSS remains one of the most successful open standards on the web.
It is simple. It is durable. It is widely supported.
However modern publishing increasingly spans multiple content types and disconnected platforms.
A site may publish:
- articles
- podcasts
- videos
- software releases
- generated reports
- structured machine-readable content
Often through entirely different mechanisms.
That fragmentation is the gap MMSP was created to address.
The goal is not to replace RSS.
The goal is to provide a standard discovery and publication layer that allows publishers to expose structured content through a common machine-readable contract while remaining compatible with existing feed ecosystems.
The MMSP specification is available at: MMSP-Spec
What it does
The everyday surface is a calm three-pane reader: RSS, Atom and MMSP subscriptions through one model, topic-based discovery, filtering, unread tracking, media rendering, import and export and full keyboard accessibility, all persisted to local SQLite. The feature catalogue lives on the product site: ernster.dev/meridian/features.
The result is not another website.
It is a local publication client.
MMSP protocol support
Meridian is the reference implementation of the MMSP specification.
MMSP introduces a standard discovery endpoint:
/.well-known/mmsp.json
Publishers expose machine-readable metadata describing available content streams and subscription endpoints. What the specification defines (discovery, feed metadata, content streams, subscription information, capabilities, interoperability rules) is catalogued on the spec site itself.
The intent is to give publishers a standard way to describe what they publish and give clients a predictable way to discover and consume it.
Unified feed consumption
Meridian consumes multiple feed formats through a common model.
Supported sources include:
- RSS
- Atom
- MMSP
Regardless of source format, feeds appear through the same interface.
The goal was simple:
Subscription should feel consistent even when publication formats differ.
Feed discovery
Finding a feed should not require knowing a feed URL.
Meridian ships a discovery panel backed by the Feedly search index. Searching by topic or keyword returns a ranked list of matching feeds. Any of them can be subscribed to immediately, individually or in bulk, without leaving the application.
The discovery layer runs on a dedicated async event loop in a background thread, completely isolated from the reader and poll scheduler. In-flight searches can be cancelled at any point.
Desktop workflow
Meridian focuses on direct consumption rather than engagement.
The interface follows a traditional three-pane reader model: feeds, items, content. Every control is reachable and operable by keyboard. Tab order is consistent throughout; list views are single tab stops with arrow-key navigation within them. Enter and Space activate any focused control. Left and Right navigate between dialog actions without lifting a hand.
Per-feed filters are managed through a dedicated dialog. When a filter already exists, it opens pre-populated with each active term displayed as a toggleable row. Terms can be deactivated individually. New terms are appended. The result is saved as a single expression.
This keeps navigation predictable even with large subscription collections.
Structured publication
The protocol is the heart of the project.
It answers a question traditional feeds only partially address:
How does a publisher describe itself, its content and its capabilities in a way that any client can discover automatically?
A publication may contain text. A publication may contain media. A publication may contain machine-generated output. A publication may contain future content types that do not yet exist.
MMSP models publication as structured content rather than a specific feed format.
The protocol tracks:
- publisher metadata
- feed definitions
- content endpoints
- discovery information
- subscription metadata
This turns publication into explicit machine-readable state.
Once publication becomes explicit, interoperability becomes possible.
Local first
Meridian is intentionally local software.
Subscriptions live on the machine. The database lives on the machine. The reader runs as a desktop application.
The project does not depend on cloud infrastructure.
That decision was deliberate.
Feed readers existed long before engagement algorithms.
The problem did not require a platform.
It required a protocol and a client.
Architecture
Meridian is a Python 3.11+ PySide6 application over local SQLite with httpx networking, persisting everything on the machine.
The complexity is not scale.
The complexity is interoperability.
A protocol only becomes useful when independent publishers and clients can communicate predictably.
The project therefore focuses heavily on explicit contracts, compatibility and structured publication.
What this taught me
Meridian reinforced a familiar engineering lesson:
A protocol becomes valuable when it creates a shared contract.
A feed format describes content. A reader consumes content. A protocol defines how systems discover and understand each other.
RSS solved that problem for an earlier web.
MMSP explores what a similar approach might look like for modern structured publication.
It is not trying to predict every future content type.
It is trying to provide a foundation that allows new content types to be described consistently.
That is why Meridian focuses on publication rather than platforms.
It is not trying to own content.
It is trying to make content easier to discover, subscribe to and consume.
Meridian is a working example of software built around open publication.
The value is not that it reads feeds.
The value is that it treats publication as a structured, machine-readable contract.